


Anthropic 正式宣佈將 Claude 1M(一百萬)token 的上下文視窗(Context Window)功能,從測試階段推向全面開放(General Availability, GA)。此次更新不僅涵蓋了旗艦模型 Claude Opus 4.6,也同步部署於高性價比的 Sonnet 4.6。對於開發者而言,這不僅是記憶體空間的擴張,更是一次基礎設施層級的優化,解決了長文本處理中長期存在的計費複雜性與效能瓶頸。
計費架構去中心化:打破長文本溢價門檻
在傳統的 LLM 服務中,處理極長上下文往往伴隨著「長度溢價」(Long-context Premium)或梯度計費。然而,Anthropic 在此次 GA 更新中採行了「單一費率」機制。這意味著模型不再區分短文本與長文本的 token 單價,全區間統一計費。
具體規格如下:
- Claude Opus 4.6:輸入每百萬 token 為 5 美元,輸出每百萬 token 為 25 美元。
- Claude Sonnet 4.6:輸入每百萬 token 為 3 美元,輸出每百萬 token 為 15 美元。
最關鍵的技術細節在於「無倍增係數」(No Multiplier)。過去,發送一個接近 1M token 的請求,系統負荷遠高於數個短請求,因此常有額外的成本負擔。現在,一個 900K 的 Request 與 9K 的 Request 在 per-token rate 上完全一致,這大幅降低了企業在預算預估上的不確定性。
吞吐量與多模態效能:6 倍視覺輸入增量
在技術吞吐量(Throughput)方面,Anthropic 解決了開發者在處理大量非文字資料時的痛點。隨著 1M 上下文的全面開放,單次請求所能包含的媒體數量從 100 份增至 600 份(包含圖片與 PDF 頁面)。這對於需要進行「跨文件視覺分析」的系統(如:自動化專利對比系統、多年度財報視覺化掃描)提供了強大的硬體級支援。
此外,速率限制(Rate Limits)現在也與上下文長度解耦。在 GA 版本中,用戶標準帳戶的速率限制將橫跨整個 1M 視窗,這意味著後端 API 不會因為請求內容過長而人為地降低吞吐頻率,確保了生產環境中 Pipeline 的穩定度。
工程簡化:從 Beta 標頭到自動化整合
在開發者體驗(DX)上,這次更新移除了所有 Beta 階段的限制。過往在使用 200K 以上的 Context 時,開發者必須在 HTTP Header 中手動加入特定標頭。GA 化後,超過 200K 的請求將由 Claude 平台自動處理,這意味著現有的 SDK 與自動化腳本無需進行任何代碼變更即可向下相容。
對於使用 Claude Code 工具的 Max、Team 與 Enterprise 用戶,Opus 4.6 的對話工作流將自動利用這 1M 的空間。從技術底層來看,這減少了「對話壓縮」(Conversation Compaction)的觸發頻率。在軟體開發場景中,這能確保完整的代碼追蹤(Code Trace)、工具呼叫(Tool Calls)以及觀察紀錄(Observations)能完整保留在 KV Cache 中,避免因摘要過程導致的邏輯斷點。
效能指標:RAG 以外的高保真選擇
一百萬 token 的空間是否具有實戰價值,取決於模型在長文本下的召回(Recall)精度。根據 Anthropic 公佈的技術數據,Opus 4.6 在 MRCR v2(多段落推理與召回測試)中取得了 78.3% 的得分,這是在同等長度下,目前尖端模型(Frontier Models)的最高紀錄。
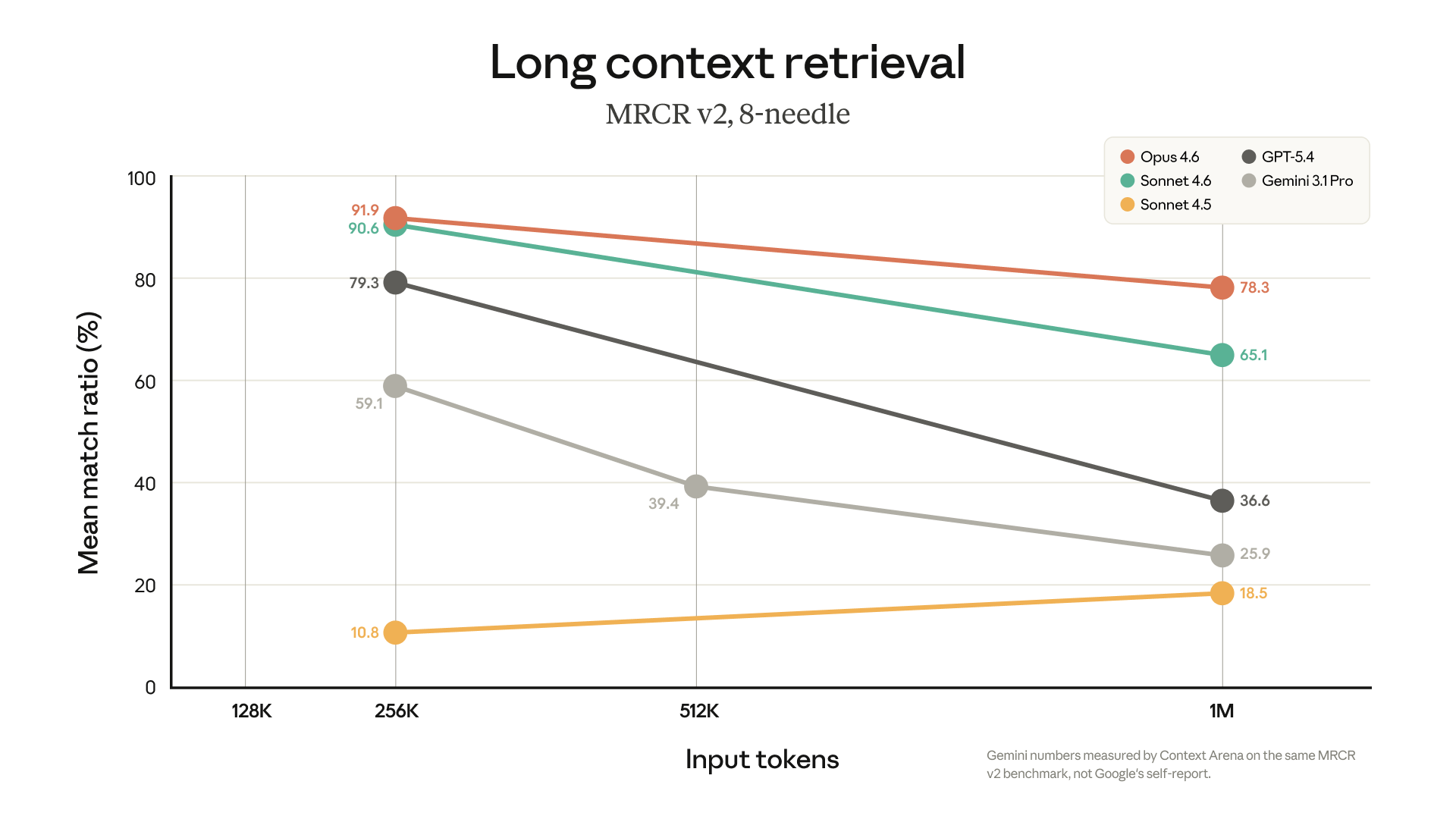 Photo Credit: Claude
Photo Credit: Claude
在許多應用場景中,開發者常需要建立複雜的 RAG(檢索增強生成)Pipeline 來處理大型代碼庫或法律卷宗,但 RAG 往往會受到向量檢索精度的限制。有了 Opus 4.6 穩定的百萬召回率,開發者可以直接將整個 Codebase 或數千頁合約載入上下文,省去了「切片(Chunking)」、「向量化(Embedding)」以及「重排序(Reranking)」等繁瑣的工程步驟,實現了「零遺漏」的上下文處理,這在對精確度要求極高的任務中,是極具競爭力的技術優勢。
目前,這項功能已在 Claude 平台、Amazon Bedrock、Google Cloud Vertex AI 以及 Microsoft Azure Foundry 全面同步上線。
責任編輯:Claire
核稿編輯:Sherlock
本文初稿由 INSIDE 使用 AI 協助編撰,並經人工審校確認;加入 INSIDE 會員,獨享 INSIDE 科技趨勢電子報,點擊立刻成為會員!
延伸閱讀:
- 別再只聽 Claude 說,看它畫給你聽!互動圖表 Beta 版登場:讓複利與週期表都動起來
- 寫程式動口不動手?Anthropic 揭 Claude Code 語音功能,同步下放記憶工具搶攻 ChatGPT 用戶
- Anthropic 遭列國安風險名單:解析供應鏈風險爭議與 Claude 霸榜背後的隱私戰火
您可能也會喜歡
OpenAI 澄清 ChatGPT 廣告僅限美國市場 承諾不影響模型中立性

澳洲政府警告年輕人四分之一持有加密貨幣,64%更信 AI 理財建議,23%跟著投資網紅操作

