

Matting Robuste Guidé par Masque : Gestion des Entrées Bruitées et de la Polyvalence des Objets
Table des liens
Résumé et 1. Introduction
-
Travaux connexes
-
MaGGIe
3.1. Matting d'instance guidé par masque efficace
3.2. Cohérence temporelle caractéristique-matte
-
Ensembles de données de matting d'instance
4.1. Matting d'instance d'image et 4.2. Matting d'instance vidéo
-
Expériences
5.1. Pré-entraînement sur les données d'image
5.2. Entraînement sur les données vidéo
-
Discussion et Références
\ Matériel supplémentaire
-
Détails de l'architecture
-
Matting d'image
8.1. Génération et préparation de l'ensemble de données
8.2. Détails de l'entraînement
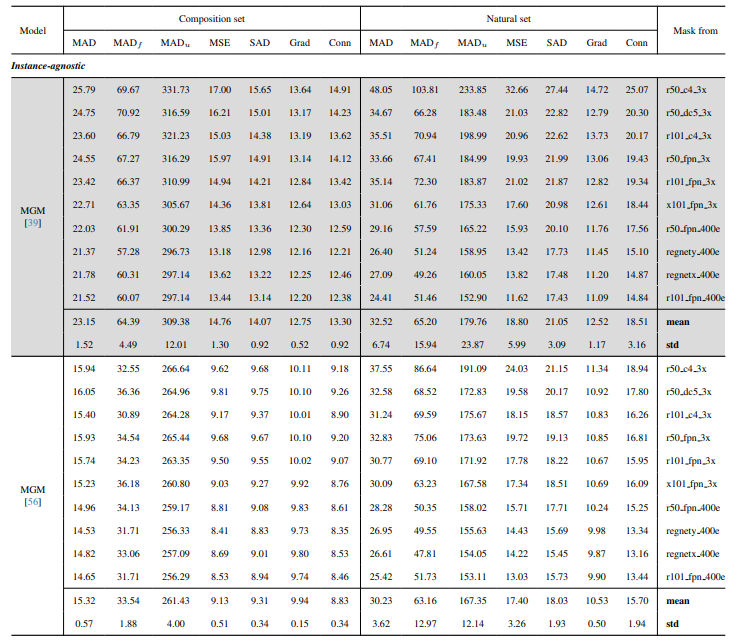
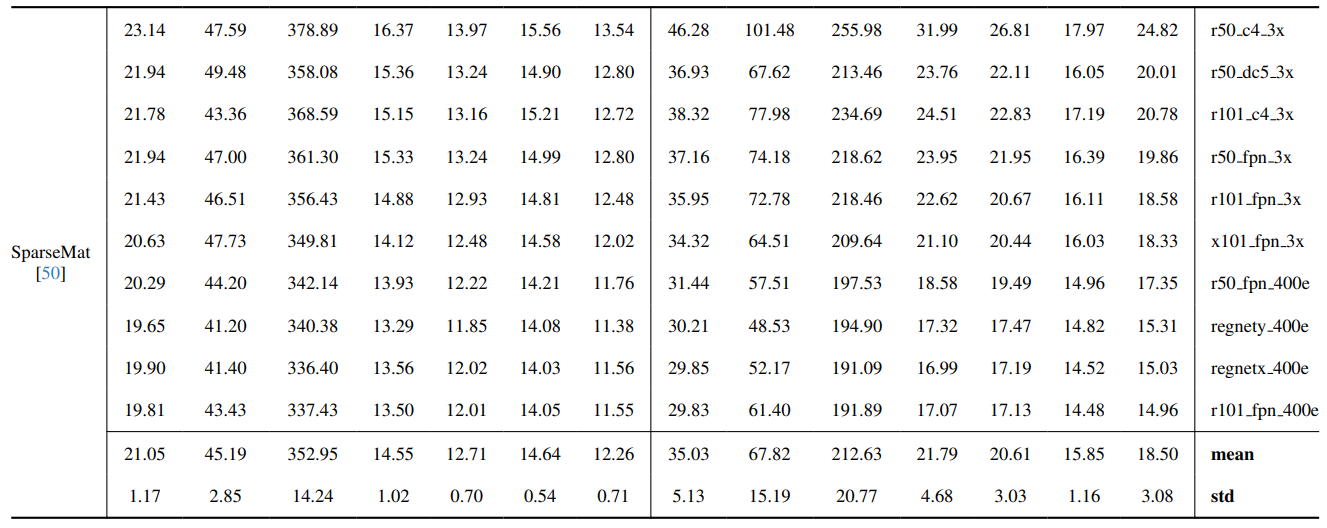
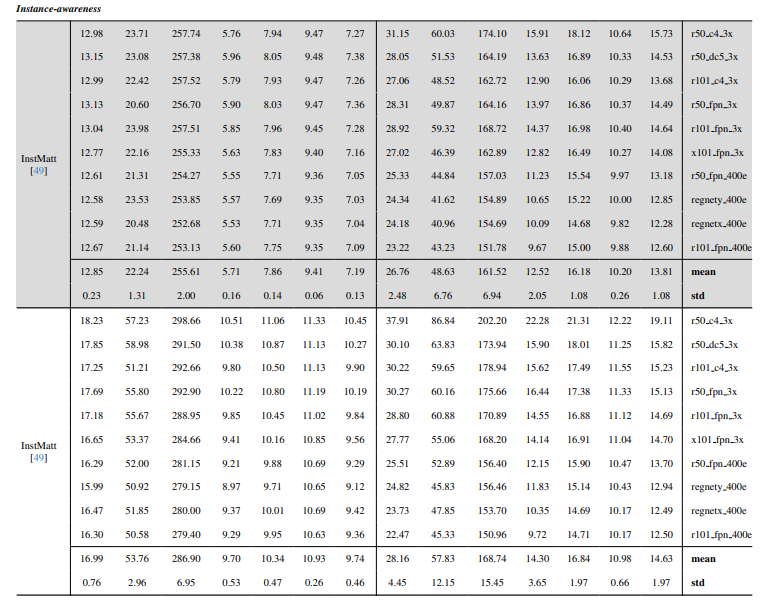
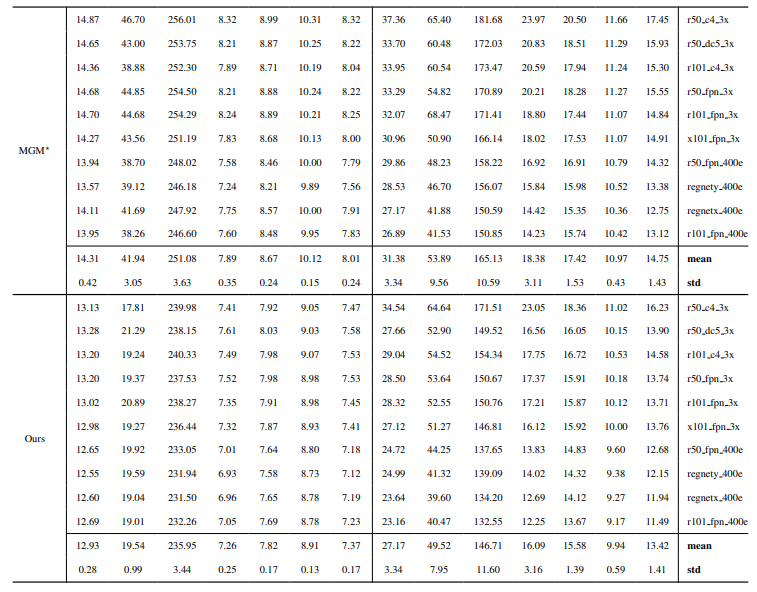
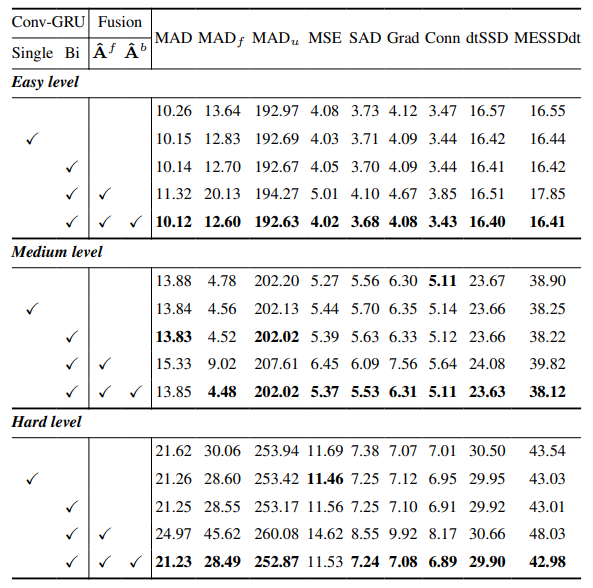
8.3. Détails quantitatifs
8.4. Plus de résultats qualitatifs sur les images naturelles
-
Matting vidéo
9.1. Génération de l'ensemble de données
9.2. Détails de l'entraînement
9.3. Détails quantitatifs
9.4. Plus de résultats qualitatifs
8.4. Plus de résultats qualitatifs sur les images naturelles
La Fig. 13 présente les performances de notre modèle dans des scénarios difficiles, en particulier pour le rendu précis des régions de cheveux. Notre framework surpasse constamment MGM⋆ en termes de préservation des détails, notamment dans les interactions d'instances complexes. En comparaison avec InstMatt, notre modèle présente une séparation d'instances et une précision des détails supérieures dans les régions ambiguës.
\ Les Fig. 14 et Fig. 15 illustrent les performances de notre modèle et des travaux précédents dans des cas extrêmes impliquant plusieurs instances. Alors que MGM⋆ rencontre des difficultés avec le bruit et la précision dans des scénarios d'instances denses, notre modèle maintient une haute précision. InstMatt, sans données d'entraînement supplémentaires, montre des limites dans ces configurations complexes.
\ La robustesse de notre approche guidée par masque est davantage démontrée dans la Fig. 16. Ici, nous soulignons les défis rencontrés par les variantes MGM et SparseMat pour prédire les parties manquantes dans les entrées de masque, que notre modèle résout. Cependant, il est important de noter que notre modèle n'est pas conçu comme un réseau de segmentation d'instances humaines. Comme le montre la Fig. 17, notre framework adhère au guidage d'entrée, assurant une prédiction précise de l'alpha matte même avec plusieurs instances dans le même masque.
\ Enfin, les Fig. 12 et Fig. 11 soulignent les capacités de généralisation de notre modèle. Le modèle extrait avec précision à la fois les sujets humains et d'autres objets des arrière-plans, démontrant sa polyvalence à travers différents scénarios et types d'objets.
\ Tous les exemples sont des images Internet sans vérité de terrain et le masque de r101fpn400e est utilisé comme guidage.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Auteurs :
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Cet article est disponible sur arxiv sous licence CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Vous aimerez peut-être aussi

Nomination de Trump suscite l'inquiétude suite à des allégations de téléportation

Trump affirme avoir construit « l'économie la plus forte de l'histoire » sans inflation



