

NEAR Achieves 1M Transactions Per Second in Sharded, Test Environment
NEAR Protocol NEAR $1.75 24h volatility: 1.1% Market cap: $2.24 B Vol. 24h: $188.81 M has achieved a significant milestone of 1 million transactions per second (TPS) in a benchmark test environment created to simulate a real-world scenario. This development helps to demonstrate sharding is an efficient method for high scalability and throughput capacity for high-performance blockchains—surpassing Visa’s peak capacity of around 65,000 transactions per second.
The NEAR Foundation reported this recent achievement in a blog post on Dec. 8, explaining the benchmark’s methodology in “a publicly verifiable benchmark using real code, realistic workloads, and cost-effective and performant Google Compute Engine C4D machines across 70 shards,” as described.
Results are available in three Grafana dashboards that achieved 1,029,497, 1,037,334, and 1,037,495 transactions per second peaks, followed by a constant one million TPS performance for nearly one hour each.
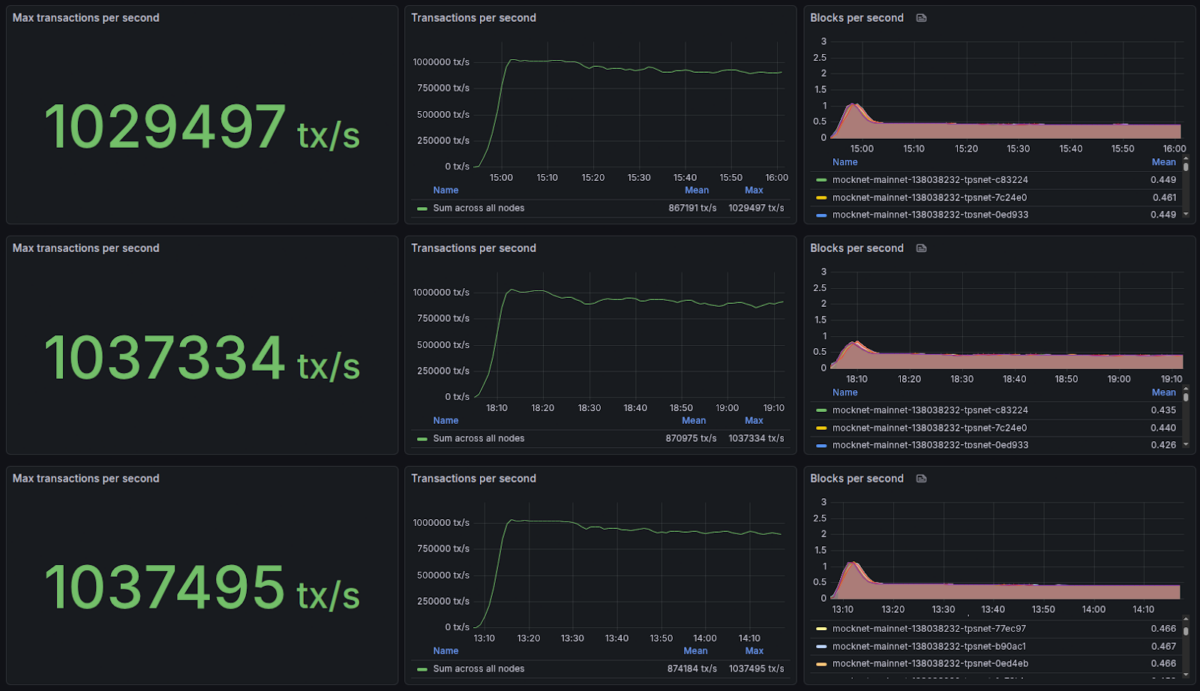
Grafana dashboards for three NEAR Protocol 1M-TPS tests | Source: NEAR Foundation/Grafana
As described in the blog post, this benchmark had validators split in 70 shards, running commercial-grade hardware from Google Cloud, with an approximate cost of $900 per month. While accessible, this cost is significantly higher than the minimum required to run chunk validators on NEAR—currently estimated at $15 per month, according to Meta Pool’s Node Studio.
This test used only native token transfers, not broadcasting smart contract executions that require more network gas and computational power, which could reduce the overall capacity per second. Moreover, the NEAR blockchain currently has nine shards and not the 70 shards used for the tests, meaning the current mainnet capacity is likely orders of magnitude below the achieved one million transactions per second.
Nevertheless, it suggests NEAR Protocol is ready, with enough optimizations, to scale at any moment to something close to 1 million TPS with consistency and network reliability as adoptions and demand for block space grows.
How Many TPS Other Blockchains and Payment Processors Can Achieve?
Interestingly, Visa (NYSE: V) can scale to 65,000 transactions per second, according to The Banking Scene. In 2024, Visa processed an average of approximately 25,091 transactions per second globally, based on the total of roughly 293 billion payment transactions handled that year.
Data Coinspeaker gathered from Chainspect on Dec. 8 shows the theoretical maximum TPS other blockchains can achieve, based on benchmark tests like the one provided by NEAR, or rough calculations by the Chainspect analysts.
When comparing with some of the largest cryptocurrencies by market cap, Sonic, ICP, and Aptos have the largest maximum theoretical TPS after NEAR, with nearly 400,000, 210,000, and 160,000 transactions per second, respectively.
Sui SUI $1.61 24h volatility: 0.9% Market cap: $6.01 B Vol. 24h: $995.44 M , TON TON $1.63 24h volatility: 1.4% Market cap: $3.98 B Vol. 24h: $135.10 M , Polkadot DOT $2.12 24h volatility: 0.7% Market cap: $3.49 B Vol. 24h: $192.42 M , and Solana SOL $134.4 24h volatility: 1.0% Market cap: $75.38 B Vol. 24h: $5.34 B follow suit, with approximately 120,000, 105,000, 100,000, and 65,000 TPS, respectively. However, SOL is the one with the highest “Real-Time TPS” across all blockchains on Chainspect—at 1,238 transactions per second by the time of this writing.
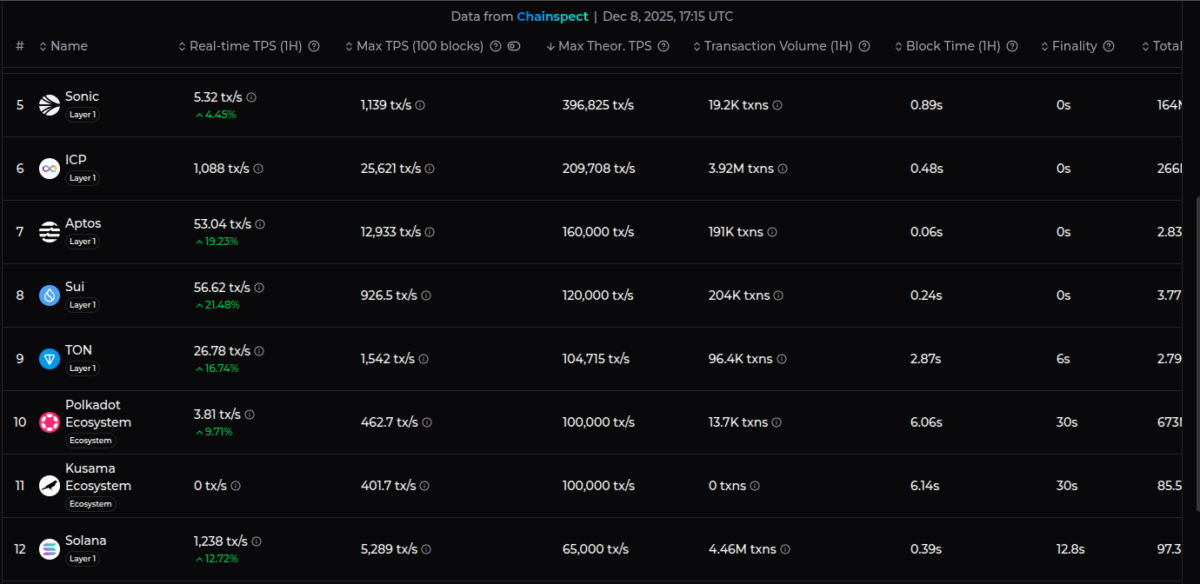
Fastest blockchains by transactions per second (TPS), as of Dec. 8 | Source: Coinspect
Therefore, this recent achievement positions NEAR as one of the layer-one blockchain networks with the highest theoretical capacity and scalability. This adds up to recent positive developments in the NEAR ecosystem, as Coinspeaker has covered and reported about.
On Dec. 5, NEAR launched TravAI, together with ADI Chain, where AI agents handle complete travel booking workflows from search to payment using crypto. On Dec. 3, the foundation announced NEAR AI Cloud and Private Chat, two related products that were already integrated by relevant players like the Brave Browser. Kalshi also recently added support to NEAR’s native token and NEAR Intents surpassed the $7 billion mark for its chain-abstracted swaps all-time volume.
nextThe post NEAR Achieves 1M Transactions Per Second in Sharded, Test Environment appeared first on Coinspeaker.
You May Also Like

21Shares Launches JitoSOL Staking ETP on Euronext for European Investors

Digital Asset Infrastructure Firm Talos Raises $45M, Valuation Hits $1.5 Billion
