

Robustes maskengeführtes Matting: Umgang mit verrauschten Eingaben und Objektvielseitigkeit
Inhaltsverzeichnis der Links
Abstrakt und 1. Einleitung
-
Verwandte Arbeiten
-
MaGGIe
3.1. Effizientes maskiertes geführtes Instanz-Matting
3.2. Feature-Matte zeitliche Konsistenz
-
Instanz-Matting-Datensätze
4.1. Bild-Instanz-Matting und 4.2. Video-Instanz-Matting
-
Experimente
5.1. Vortraining auf Bilddaten
5.2. Training auf Videodaten
-
Diskussion und Referenzen
\ Ergänzendes Material
-
Architekturdetails
-
Bild-Matting
8.1. Datensatzerzeugung und -vorbereitung
8.2. Trainingsdetails
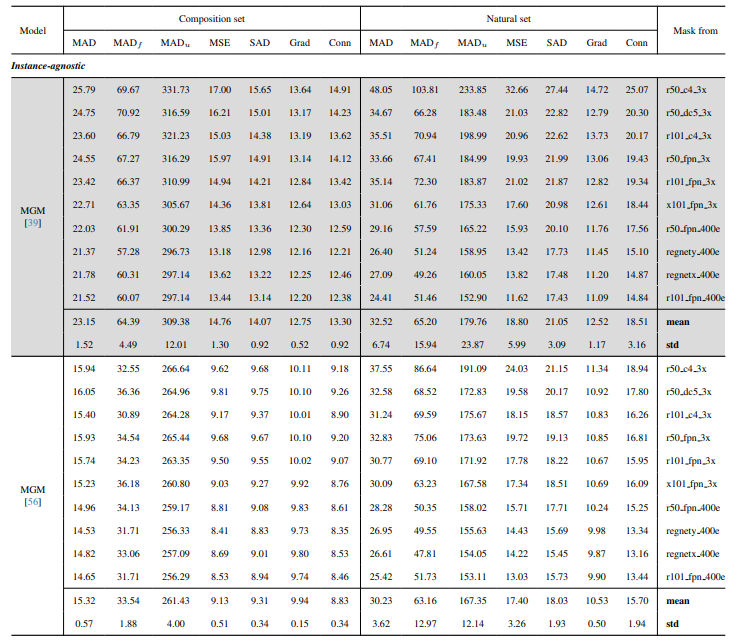
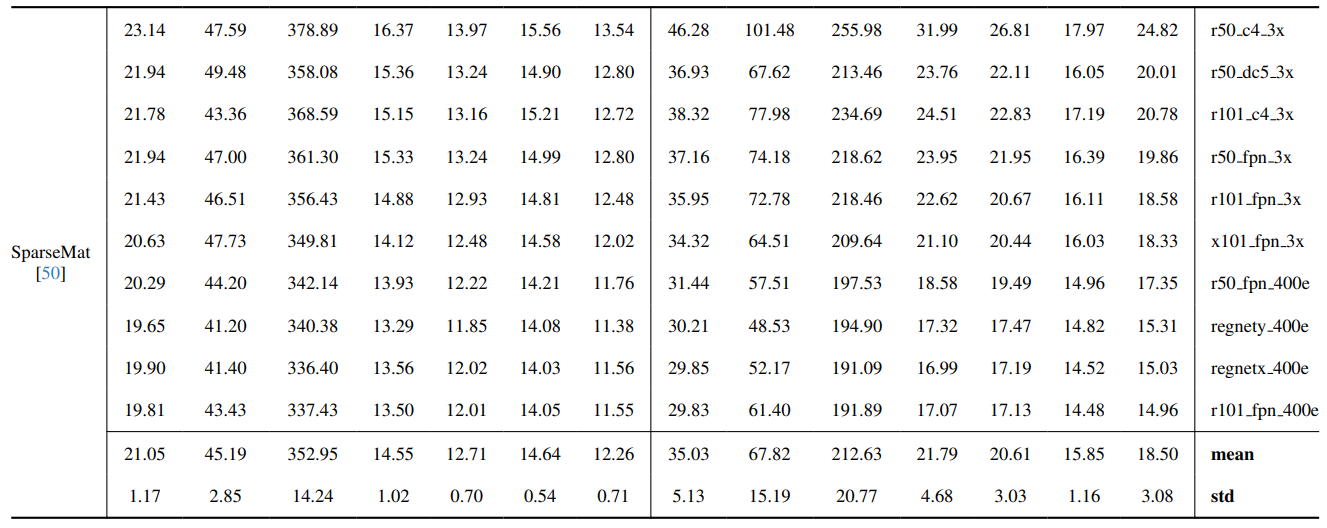
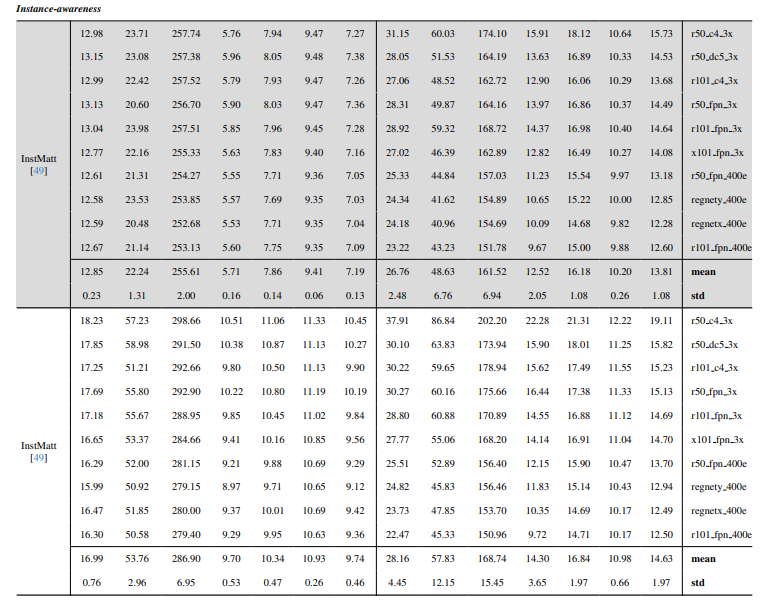
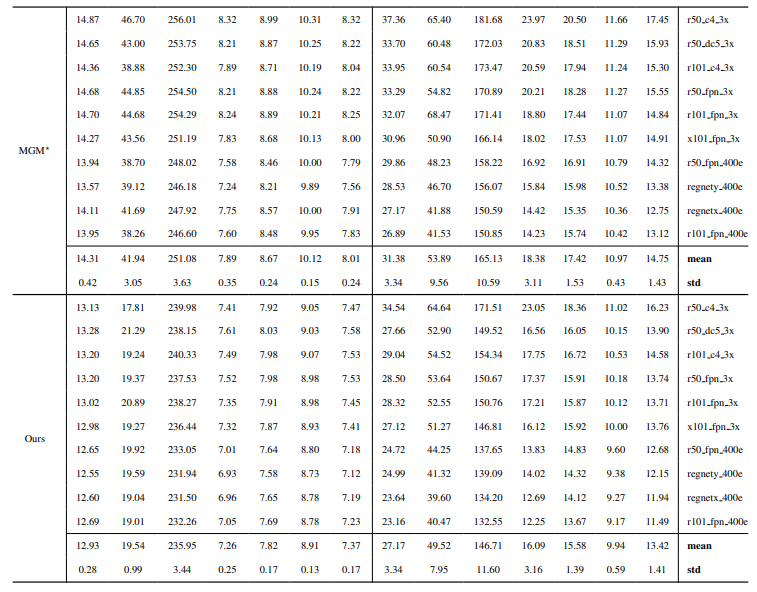
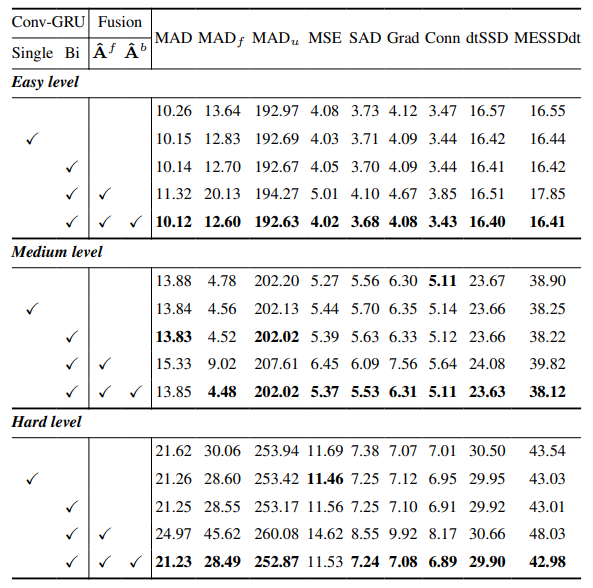
8.3. Quantitative Details
8.4. Weitere qualitative Ergebnisse auf natürlichen Bildern
-
Video-Matting
9.1. Datensatzerzeugung
9.2. Trainingsdetails
9.3. Quantitative Details
9.4. Weitere qualitative Ergebnisse
8.4. Weitere qualitative Ergebnisse auf natürlichen Bildern
Abb. 13 zeigt die Leistung unseres Modells in herausfordernden Szenarien, insbesondere bei der genauen Darstellung von Haarbereichen. Unser Framework übertrifft MGM⋆ durchgehend in der Detailerhaltung, besonders bei komplexen Instanzinteraktionen. Im Vergleich mit InstMatt zeigt unser Modell eine überlegene Instanztrennung und Detailgenauigkeit in mehrdeutigen Bereichen.
\ Abb. 14 und Abb. 15 veranschaulichen die Leistung unseres Modells und früherer Arbeiten in Extremfällen mit mehreren Instanzen. Während MGM⋆ mit Rauschen und Genauigkeit in dichten Instanzszenarien zu kämpfen hat, behält unser Modell hohe Präzision bei. InstMatt zeigt ohne zusätzliche Trainingsdaten Einschränkungen in diesen komplexen Umgebungen.
\ Die Robustheit unseres maskengeführten Ansatzes wird weiter in Abb. 16 demonstriert. Hier heben wir die Herausforderungen hervor, mit denen MGM-Varianten und SparseMat bei der Vorhersage fehlender Teile in Maskeneingaben konfrontiert sind, die unser Modell adressiert. Es ist jedoch wichtig zu beachten, dass unser Modell nicht als menschliches Instanzsegmentierungsnetzwerk konzipiert ist. Wie in Abb. 17 gezeigt, hält sich unser Framework an die Eingabeführung und gewährleistet präzise Alpha-Matte-Vorhersagen selbst bei mehreren Instanzen in derselben Maske.
\ Schließlich betonen Abb. 12 und Abb. 11 die Generalisierungsfähigkeiten unseres Modells. Das Modell extrahiert sowohl menschliche Subjekte als auch andere Objekte präzise aus Hintergründen und zeigt seine Vielseitigkeit über verschiedene Szenarien und Objekttypen hinweg.
\ Alle Beispiele sind Internetbilder ohne Ground-Truth und die Maske von r101fpn400e wird als Führung verwendet.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autoren:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Dieses Papier ist auf arxiv verfügbar unter CC by 4.0 Deed (Attribution 4.0 International) Lizenz.
:::
\
Das könnte Ihnen auch gefallen

Robert Kiyosaki hebt Bitcoin-Strategie hervor, während er vor drohendem Marktcrash-Risiko warnt – Featured Bitcoin News

Kalshi sieht sich bundesweiten Klagen gegenüber, da Prognosemärkte als „getarnte Glücksspiele" bezeichnet werden


