

সিস্টেম টেবিল ছাড়াই Databricks ক্লাস্টার খরচ এবং ব্যবহার অপ্টিমাইজ করা
বেশিরভাগ এন্টারপ্রাইজ Databricks পরিবেশে (MSC বা বড় অ্যানালিটিক্স ইকোসিস্টেমের মতো), সিস্টেম টেবিল যেমন system.job_run_logs বা system.cluster_events সিকিউরিটি বা গভর্ন্যান্স নীতির কারণে সীমাবদ্ধ বা নিষ্ক্রিয় থাকতে পারে।
তবে, ক্লাস্টার ব্যবহার এবং খরচ ট্র্যাক করা অত্যন্ত গুরুত্বপূর্ণ:
- জবগুলি কতটা দক্ষতার সাথে কম্পিউট ব্যবহার করে তা বোঝার জন্য
- নিষ্ক্রিয় ক্লাস্টার বা খরচ লিক চিহ্নিত করার জন্য
- অবকাঠামো বাজেট পূর্বাভাস দেওয়ার জন্য
- কাস্টম খরচ ড্যাশবোর্ড তৈরি করার জন্য
এই ব্লগটি শুধুমাত্র Databricks REST APIs ব্যবহার করে ক্লাস্টার ব্যবহার এবং খরচ গণনা করার একটি ধাপে ধাপে পদ্ধতি প্রদর্শন করে — কোনো সিস্টেম টেবিলের প্রয়োজন নেই।
প্রজেক্ট ব্যবহার কেস
আমাদের MSC ডেটা প্ল্যাটফর্মে, আমরা ডেভেলপমেন্ট, টেস্ট এবং প্রোডাকশন জুড়ে একাধিক Databricks ক্লাস্টার চালাই। \n আমাদের তিনটি প্রধান চ্যালেঞ্জ ছিল:
- সিস্টেম টেবিলে কোনো অ্যাক্সেস নেই (অ্যাডমিন নীতি দ্বারা সীমাবদ্ধ)
- ADF বা অর্কেস্ট্রেশন পাইপলাইন দ্বারা ডায়নামিকভাবে তৈরি জবের জন্য ক্ষণস্থায়ী ক্লাস্টার
- ক্লাস্টার ব্যবহার কীভাবে খরচে রূপান্তরিত হয় তার কোনো সরাসরি দৃশ্য নেই
তাই, আমরা একটি লাইটওয়েট ব্যবহার বিশ্লেষক তৈরি করেছি যা:
- Databricks REST APIs থেকে ডেটা টানে
- জব রানটাইম বনাম ক্লাস্টার রানটাইম গণনা করে
- DBU এবং VM রেট ব্যবহার করে খরচ অনুমান করে
- একটি সহজে ব্যবহারযোগ্য DataFrame আউটপুট করে
সমস্যা এবং পদ্ধতি
চিহ্নিত চ্যালেঞ্জ
টিমগুলির প্রায়শই জানা প্রয়োজন:
- কোন ক্লাস্টারগুলি নিষ্ক্রিয় (কম জব কার্যকলাপ সহ চলছে)?
- ব্যবহার % কত (জব রানটাইম বনাম ক্লাস্টার আপটাইম)?
- প্রতিটি ক্লাস্টার কত খরচ করছে (DBU + VM)?
যখন Unity Catalog সিস্টেম টেবিল (যেমন, system.job_run_logs) অনুপলব্ধ থাকে, তখন ডিফল্ট SQL-ভিত্তিক পদ্ধতি ব্যর্থ হয়। REST API নির্ভরযোগ্য বিকল্প হয়ে ওঠে।
নোটবুকে ব্যবহৃত উচ্চ-স্তরের পদ্ধতি
- /api/2.0/clusters/list এর মাধ্যমে ক্লাস্টার তালিকা তৈরি করুন।
- ক্লাস্টার JSON-এর ভিতরে টাইমস্ট্যাম্প ব্যবহার করে ক্লাস্টার আপটাইম অনুমান করুন (created/start/terminated ফিল্ড)। (যখন /clusters/events অনুপলব্ধ থাকে তখন এটি একটি বাস্তবসম্মত বিকল্প।)
- টাইম ফিল্টার (বা লিমিট) সহ /api/2.1/jobs/runs/list ব্যবহার করে সাম্প্রতিক জব রান পান।
- cluster_instance.cluster_id (বা অন্যান্য ক্লাস্টার মেটাডেটা) ব্যবহার করে জব রানগুলি ক্লাস্টারের সাথে মিলান করুন।
- ব্যবহার গণনা করুন: ব্যবহার % = total_job_runtime / total_cluster_uptime।
- একটি সহজ সূত্র ব্যবহার করে খরচ অনুমান করুন: খরচ = running_hours × (DBU/hr × assumed DBU) + running_hours × nodes × VM $/hr।
এই নোটবুকটি ইচ্ছাকৃতভাবে বাউন্ডেড কোয়েরি (শেষ N রান, টাইম উইন্ডো) ব্যবহার করে যাতে এটি দ্রুত চলে।
\ ১. সেটআপ এবং কনফিগারেশন
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ এই অংশটি শুরু করে:
- অথেন্টিকেশনের জন্য ওয়ার্কস্পেস URL এবং টোকেন
- আপনি যে সময়সীমার জন্য ব্যবহার বিশ্লেষণ করতে চান
- খরচের অনুমান:
- DBU রেট ($/hr প্রতি DBU)
- VM নোড খরচ
- আনুমানিক DBU খরচ
এন্টারপ্রাইজ সেটআপে, এই রেটগুলি আপনার FinOps বা বিলিং APIs এর মাধ্যমে ডায়নামিকভাবে আনা যেতে পারে।
-
API র্যাপার ফাংশন
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ এই হেল্পার ফাংশনটি সমস্ত REST API GET কল স্ট্যান্ডার্ডাইজ করে। \n এটি:
-
সম্পূর্ণ এন্ডপয়েন্ট URL তৈরি করে
-
404 কে সুন্দরভাবে পরিচালনা করে (যখন ক্লাস্টার বা রান মেয়াদ শেষ হয়ে যায় তখন গুরুত্বপূর্ণ)
-
পার্স করা JSON রিটার্ন করে
কেন এটি গুরুত্বপূর্ণ: এই ফাংশনটি নিশ্চিত করে পরিষ্কার API যোগাযোগ যদি কোনো ক্লাস্টার ডেটা অনুপস্থিত থাকে তবে আপনার নোটবুক প্রবাহ ভাঙা ছাড়াই।
\
-
সকল সক্রিয় ক্লাস্টার তালিকা
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ এটি আপনার ওয়ার্কস্পেসে উপলব্ধ সমস্ত ক্লাস্টার পুনরুদ্ধার করে। \n এটি প্রোগ্রাম্যাটিকভাবে আপনার "Compute" ট্যাব দেখার সমতুল্য। \n প্রতিক্রিয়ায় রয়েছে:
-
ক্লাস্টার আইডি
-
নাম
-
নোড সংখ্যা
-
নির্মাতার তথ্য
-
তৈরি এবং সমাপ্তির সময়
ব্যবহার কেস: নির্বাচিত উইন্ডোতে কোন ক্লাস্টারগুলি সম্পদ খরচ করছে তা চিহ্নিত করতে সহায়তা করে।
৪. ক্লাস্টার রানটাইম অনুমান করুন
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ আমরা প্রতিটি ক্লাস্টারের জন্য মোট চলমান ঘন্টা গণনা করি:
-
তৈরি এবং সমাপ্তি টাইমস্ট্যাম্প ব্যবহার করে
-
বর্তমানে চলমান ক্লাস্টার পরিচালনা করে (terminated_time অনুপস্থিত)
-
ঘন্টায় স্বাভাবিক করে
কেন এটি গুরুত্বপূর্ণ: এই মানটি ব্যবহারের জন্য হর — উইন্ডোর সময় মোট ক্লাস্টার আপটাইম প্রতিনিধিত্ব করে।
৫. সাম্প্রতিক জব রান পান
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ সম্পূর্ণ জব ইতিহাস আনার পরিবর্তে (যা ধীর), \n এই ফাংশনটি দ্রুত নির্ণয়ের জন্য সর্বাধিক সাম্প্রতিক ১০টি জব রান পুনরুদ্ধার করে।
প্রোডাকশনে, আপনি এর দ্বারা ফিল্টার করতে পারেন:
- নির্দিষ্ট job_id
- completed_only=true
- তারিখ উইন্ডো (start_time_from, start_time_to)
\
-
ব্যবহার এবং খরচ গণনা করুন
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
এটি লজিকের হৃদয়:
-
প্রতিটি ক্লাস্টারের মাধ্যমে লুপ করে
-
ক্লাস্টার প্রতি মোট জব রানটাইম গণনা করে (জব রান API ব্যবহার করে)
-
ব্যবহার শতাংশ = (job_hours / cluster_running_hours) × 100 উৎপন্ন করে
-
খরচ অনুমান করুন:
- রেট × DBU/hr এর উপর ভিত্তি করে DBU খরচ
- VM খরচ = node_count × node_cost/hr × running_hours
কেন এটি গুরুত্বপূর্ণ: \n এটি দক্ষতা এবং ব্যয়ের একটি একীভূত চিত্র দেয় — উচ্চ খরচ কিন্তু কম ব্যবহার সহ ক্লাস্টার চিহ্নিত করার জন্য দরকারী।
৭. পাইপলাইন পরিচালনা করুন
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ এই চূড়ান্ত ব্লকটি:
-
ডেটা পুনরুদ্ধার করে
-
খরচ গণনা সম্পাদন করে
-
সাজানো Data Frame প্রদর্শন করে
বাস্তবে, এই Data Frame হতে পারে:
-
Excel বা Delta Table-এ রপ্তানি করা
-
Power BI ড্যাশবোর্ডে পাঠানো
-
FinOps অটোমেশন পাইপলাইনে একীভূত করা
\
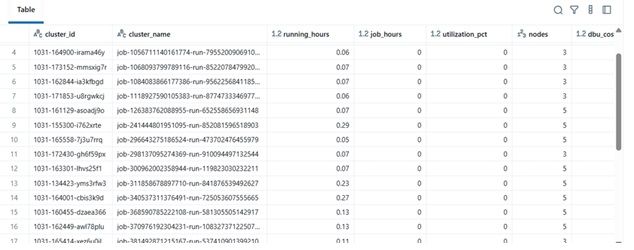
ফলাফল উদাহরণ
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
বাস্তব-বিশ্বের সুবিধা
এই বিশ্লেষক বাস্তবায়ন করে:
-
ইঞ্জিনিয়ারিং টিম অডিট অ্যাক্সেস ছাড়াই ক্লাস্টার খরচ ট্র্যাক করতে পারে।
-
ম্যানেজাররা কম-ব্যবহৃত ক্লাস্টারে দৃশ্যমানতা পান।
-
DevOps স্বয়ংক্রিয়ভাবে কম-ব্যবহারের ক্লাস্টার বন্ধ করতে পারে।
-
ফিন্যান্স অভ্যন্তরীণ মেট্রিক্স দিয়ে Databricks ইনভয়েস যাচাই করতে পারে।
আমাদের MSC প্রজেক্টে, আমরা এটিকে আমাদের ডেটা প্ল্যাটফর্ম পর্যবেক্ষণযোগ্যতা স্ট্যাকের অংশ হিসাবে ব্যবহার করেছি — REST API ডেটা, ADF জব লগ এবং খরচের প্রবণতা একটি একীভূত ড্যাশবোর্ডে একত্রিত করে।
\
আপনি আরও পছন্দ করতে পারেন

ন্যাসড্যাক এবং CME নতুন ন্যাসড্যাক-CME ক্রিপ্টো ইনডেক্স লঞ্চ করেছে—ডিজিটাল সম্পদের ক্ষেত্রে একটি গেম-চেঞ্জার

CLARITY আইনের সিনেট ব্যাংকিং কমিটিতে দ্বিদলীয় সমর্থন প্রয়োজন: বিশ্লেষক
